

Eine Kleine Vectorized Classification
For the new version of my SIMD Zig parser I gave a talk about on October 10, I came up with a slightly better technique for Vectorized Classification than the one used by Langdale and Lemire (2019) for simdjson, in that it stacks slightly better.
Vectorized Classification solves the problem of quickly mapping some bytes to some sets. For my use case, I just want to figure out which characters in a vector called chunk match any of the following:
const single_char_ops = [_]u8{ '~', ':', ';', '[', ']', '?', '(', ')', '{', '}', ',' };
To do this, I create a shuffle vector that we will pass into the table parameter of vpshufb. vpshufb is an x86-64 instruction that takes a table vector and an indices vector, and returns a vector where the value at position i becomes table[indices[i]] for each 16-byte section of the table and indices. Depending on how new a machine is, this allows us to lookup 32 or 64 bytes simultaneously into a 16-byte lookup table (one could also use a different 16-byte table for each 16-byte chunk, but typically we duplicate the same 16-byte table for each chunk). Here is how it is depicted on officedaytime.com:
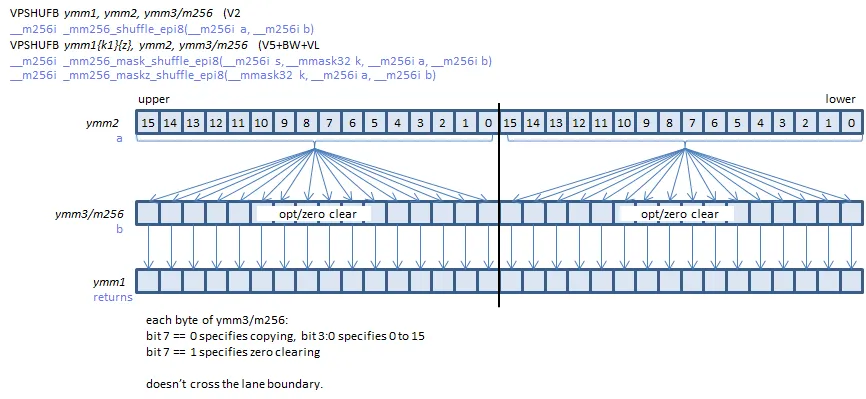
Here is the table generator:
comptime var table: @Vector(16, u8) = @splat(0);
inline for (single_char_ops) |c|
table[c & 0xF] |= 1 << (c >> 4);
As you can see, the index we store data at is c & 0xF where c is each of { '~', ':', ';', '[', ']', '?', '(', ')', '{', '}', ',' }. The data we associate with the low nibble given by c & 0xF is 1 << (c >> 4). This takes the upper nibble, and then shifts 1 left by that amount. This allows us to store up to 8 valid upper nibbles (corresponding to the number of bits in a byte), in the range . This isn’t quite , the actual range of a nibble (4 bits), but for our use-case, we only are matching ascii characters, so this limitation does not affect us. Then we just have to do the same transform 1 << (c >> 4) on the data in chunk and do a bitwise & to test if the upper nibble we found matches one of the valid options.
E.g. ; is 0x3B in hex, so we do table[0x3B & 0xF] |= 1 << (0x3B >> 4);, which reduces to table[0xB] |= 1 << 0x3;, which becomes table[0xB] |= 0b00001000;. [ is 0x5B, so we do table[0xB] |= 0b00100000;. { is 0x7B, so we do table[0xB] |= 0b10000000;. In the end, table[0xB] is set to 0b10101000. This tells us that 3, 5, and 7 are the valid upper nibbles corresponding to a lower nibble of 0xB.
We can query table for each value in chunk like so:
vpshufb(table, chunk);
Just ~2 cycles later, we will have completed 32 or 64 lookups simultaneously! Note that we don’t have to take the lower 4 bits via & 0xF, because vpshufb does that automatically unless the upper nibble is 8 or above, i.e. when the byte is 128 or higher. For those bytes, vpshufb will zero the result, regardless of what’s in the table. However, we already said we don’t care about non-ascii bytes for this problem, so we are fine with those being zeroed out.
Now all we need to do is verify that the upper nibble matches the data we stored in table.
To do so, we can produce a vector like so:
const upper_nibbles_as_bit_pos = @as(@TypeOf(Chunk), @splat(1)) << (chunk >> @splat(4));
Unfortunately, at the moment, LLVM gives us a pretty expensive assembly routine for the above line of code (Godbolt link):
.LCPI0_1:
.zero 32,16
.LCPI0_2:
.zero 32,252
.LCPI0_3:
.zero 32,224
.LCPI0_4:
.byte 1
foo:
vpsllw ymm0, ymm0, 5
vpbroadcastb ymm1, byte ptr [rip + .LCPI0_4]
vpblendvb ymm1, ymm1, ymmword ptr [rip + .LCPI0_1], ymm0
vpand ymm0, ymm0, ymmword ptr [rip + .LCPI0_3]
vpsllw ymm2, ymm1, 2
vpand ymm2, ymm2, ymmword ptr [rip + .LCPI0_2]
vpaddb ymm0, ymm0, ymm0
vpblendvb ymm1, ymm1, ymm2, ymm0
vpaddb ymm0, ymm0, ymm0
vpaddb ymm2, ymm1, ymm1
vpblendvb ymm0, ymm1, ymm2, ymm0
ret
Luckily, there is a very easy way to map nibbles to a byte. Use vpshufb again! Actually this works out better for us because we can map upper nibbles in the range to 0xFF. We’ll see why later.
comptime var powers_of_2_up_to_128: [16]u8 = undefined;
inline for (&powers_of_2_up_to_128, 0..) |*slot, i| slot.* = if (i < 8) @as(u8, 1) << i else 0xFF;
const upper_nibbles_as_bit_pos = vpshufb(powers_of_2_up_to_128, chunk >> @splat(4));
Much better emit! (Godbolt link)
.LCPI0_0:
...
.LCPI0_2:
...
foo2:
vpsrlw ymm0, ymm0, 4
vpand ymm0, ymm0, ymmword ptr [rip + .LCPI0_0]
vpbroadcastb ymm1, byte ptr [rip + .LCPI0_2]
vpshufb ymm0, ymm1, ymm0
ret
Now we simply bitwise & the two together, and check if it is non-0 on AVX-512 targets, else we check it for equality against the upper_nibbles_as_bit_pos bitstring. I wrote a helper function for this:
fn intersect_byte_halves(a: anytype, b: anytype) std.meta.Int(.unsigned, @typeInfo(@TypeOf(a, b)).vector.len) {
return @bitCast(if (comptime std.Target.x86.featureSetHas(builtin.cpu.features, .avx512bw))
@as(@TypeOf(a, b), @splat(0)) != (a & b)
else
a == (a & b));
}
This gives us better emit on AVX-512 because we have vptestmb, which does the whole @as(@TypeOf(a, b), @splat(0)) != (a & b) in one instruction, without even using a vector of zeroes! On AVX2 targets, we have to use a bitwise & either way, and to do a vectorized-not-equal we have to use vpcmpb+not. Hence, we avoid that extra not by instead checking a == (a & b)), where a has to be the bitstring that has only a single bit set, which is upper_nibbles_as_bit_pos for our problem.
So here is everything put together:
const single_char_ops = [_]u8{ '~', ':', ';', '[', ']', '?', '(', ')', '{', '}', ',' };
comptime var table: @Vector(16, u8) = @splat(0);
inline for (single_char_ops) |c| table[c & 0xF] |= 1 << (c >> 4);
comptime var powers_of_2_up_to_128: [16]u8 = undefined;
inline for (&powers_of_2_up_to_128, 0..) |*slot, i| slot.* = if (i < 8) @as(u8, 1) << i else 0xFF;
const upper_nibbles_as_bit_pos = vpshufb(powers_of_2_up_to_128, chunk >> @splat(4));
const symbol_mask = intersect_byte_halves(upper_nibbles_as_bit_pos, vpshufb(table, chunk));
NOTEThis properly produces a
0corresponding to bytes inchunkin the range . This is becausevpshufb(table, chunk)will produce a0for bytes inchunkin the range andvpshufb(powers_of_2_up_to_128, chunk >> @splat(4))will produce0xFFfor them.intersect_byte_halveson AVX-512 will do0 != (a & b), whereais0xFFandbis0, which will reduce to0 != 0, which isfalse. On non-AVX-512 targets,intersect_byte_halveswill doa == (a & b). Substituting the same values foraandb, we get0xFF == (0xFF & 0). This properly producesfalseas well.
Compiled for Zen 3, we get (Godbolt link):
.LCPI0_0:
.zero 32,15
.LCPI0_3:
...
.LCPI0_4:
...
findCharsInSet:
vpsrlw ymm1, ymm0, 4
vbroadcasti128 ymm3, xmmword ptr [rip + .LCPI0_3]
vpand ymm1, ymm1, ymmword ptr [rip + .LCPI0_0]
vbroadcasti128 ymm2, xmmword ptr [rip + .LCPI0_4]
vpshufb ymm1, ymm2, ymm1
vpshufb ymm0, ymm3, ymm0
vpand ymm0, ymm0, ymm1
vpcmpeqb ymm0, ymm0, ymm1
vpmovmskb eax, ymm0
vzeroupper
ret
Compiled for Zen 4, we get (Godbolt link):
.LCPI0_3:
...
.LCPI0_4:
...
.LCPI0_5:
...
findCharsInSet:
vgf2p8affineqb ymm1, ymm0, qword ptr [rip + .LCPI0_3]{1to4}, 0
vbroadcasti128 ymm2, xmmword ptr [rip + .LCPI0_4]
vbroadcasti128 ymm3, xmmword ptr [rip + .LCPI0_5]
vpshufb ymm0, ymm3, ymm0
vpshufb ymm1, ymm2, ymm1
vptestmb k0, ymm0, ymm1
kmovd eax, k0
vzeroupper
ret
The advantage of this strategy over the one used by Langdale and Lemire (2019) for simdjson is that we can reuse the vector containing the upper nibbles as a bit position (1 << (c >> 4)) if we want to do more Vectorized Classification. That means we can add more Vectorized Classification routines and only have to pay the cost for the lower nibbles, avoiding the need for an additional vbroadcasti128+vpshufb pair for the upper nibbles. To add another table, the additional overhead for Zen 3 is just vbroadcasti128+vpshufb+vpand+vpcmpeqb+vpmovmskb. For Zen 4, it’s just vbroadcasti128+vpshufb+vptestmb+kmovd.
Dare I say this is…
‒ Validark
Note from Geoff Langdale:The simdjson PSHUFB lookup is essentially borrowed from Hyperscan’s own shufti/Teddy (shufti is a acceleration technique for NFA/DFA execution, while Teddy is a full-on string matcher, but both use similar techniques). The code in question is in https://github.com/intel/hyperscan/blob/master/src/nfa/shufti.c and https://github.com/intel/hyperscan/blob/master/src/nfa/truffle.c albeit kind of difficult to read (since there’s a lot of extra magic for all the various platforms etc). Shufti is a 2-PSHUFB thing that is used “usually”, truffle is “this will always work” and uses a technique kind of similar to yours (albeit for different reasons).